観る碁のための囲碁入門24
李世乭vs.AlphaGoの対決があと1日と迫りました。
今回は番外編として、AlphaGoをご紹介します。
AlphaGoとは
Google DeepMind社が開発した、コンピュータ囲碁システムです。
Google DeepMind社は元々はイギリスのDeepMind Technologiesという人工知能のベンチャでした。
TVゲームをプレイしながら学習していく人工知能を発表して一躍有名となり、Facebookも買収に乗り出していたようですが、2014年頭にGoogleが買収に成功しました。
Googleの一員となってから、上記の人工知能をDQNという名前で発表しニュースになっています。
このGoogle DeepMind社が、2016年1月27日、科学論文誌Natureに中国のプロ棋士でヨーロッパチャンピオンの樊麾二段に5戦5勝したという実績を合わせてコンピュータ囲碁システムを発表し、同時に李世乭九段と番勝負を行うことを発表しました。
このニュースは、多少なりともコンピュータ囲碁の現状について知っている者には衝撃でした。どのくらいの衝撃かというと、おそらく、アポロ計画を知らず、地球を回る人工衛星打ち上げロケットしか知らない人が、突然、「人類が月面に降りて帰ってきました」と言われるぐらいの衝撃です。
AlphaGoが発表される前、つまり1月26日までは、コンピュータ囲碁はプロ棋士に対して石を先に3つ置いても勝てないぐらい決定的な差がありました。たいていのアマチュアには勝つぐらい強くなっていたのですが、プロに勝つにはまだ10年以上かかるだろうというのが開発関係者の印象だったのです。
AlphaGoがそもそもハードウェアの仕様が桁違いだったことは、観る碁のための囲碁入門1で触れました。
詳しい内容を知るには、Natureに載った論文のプレプリントを見ることができます。
"Mastering the Game of Go with Deep Neural Networks and Tree Search"
ちょっと論文を覗いてみましょう。
盤面(19x19の黒白空点情報)からニューラルネットワークを使って局面の特徴を抽出するのですが、「方針ネットワーク」と「価値ネットワーク」との2つを使って、読みの深さや広さを軽減しているようです。
ニューラルネットワークというのは人の脳の仕組みを荒っぽく真似たものです。層構造のものがよく使われていて、AlphaGoが使っているものもそれです。ニューラルネットワークはニューロン(あちこち繋がっている点)のつながり具合を学習することで、入力に対して役立つ出力をするようになります。
方針ネットワークは局面から次の一手を予想するニューラルネットワークです。KGSというインターネット碁会所で高段者が打った碁の3000万局面を学習し、次の一手の57%を当てることができるようになったそうです。
さらに方針ネットワーク同士で自己対戦してより勝ちやすい手を選ぶように学習します。
方針ネットワークは、形や筋、大局観を担当しているようです。
価値ネットワークは局面を見てどちらが勝つか予想するニューラルネットワークです。
価値ネットワークは形勢判断担当ですね。
ところで、AlphaGoより前のコンピュータ囲碁プログラムはどんなことをしていたのでしょう?
実はこの部分がとても面白いのです。
2008年までコンピュータ囲碁プログラムはプロ棋士に先に9手のハンデをもらってもなかなか勝てませんでした。
ところが、2008年にCrazyStoneというコンピュータ囲碁プログラムが登場して、プロ棋士に8手のハンデで勝ったのです。これはブレイクスルーでした。
このCrazyStone、従来のコンピュータ囲碁プログラムとは全く違った方法を取りました。
従来は、次の一手をデータの中から選択して手を進め、形勢判断をして、手を選ぶという一見人にとっては当たり前の方法を取っていましたが、形勢判断の部分をプログラムにするのが非常に難しかったのです。確かに将来フリカワリをした後どっちがいいかとか人間でもかなりの棋力を要します。
CrazyStoneは形勢判断をやめて、何局もランダムに最後まで打つことにしたのです。そして勝ちやすい方が優勢だと。
「局面に差があれば、同じ棋力の人が打てば局面がいい方が勝ちやすい」という常に正しいわけではないですが、もっともらしい原理が根底にあります。
ちょっと脱線しますが、皆さんはスロットマシンをされたことがありますか?
コインの出やすさが色々違うスロットマシンがたくさんあって、出やすさはわからない時、どう賭け続けるのがいいか理論的に解明した人がいます。
全部のスロットマシンに何度も賭けてみて、一番確率のいいマシンを探し出して、残りのコインをそこに賭けるという方法が思い浮かびますが、これは確率の悪いマシンにも相当数のコインを賭けていて効率が悪いです。
とりあえず一度は賭けてみますが、次はコインが出たマシンに賭けやすくします。出やすいマシンには多めに、出にくいマシンには少なめにという戦略でできるだけ損を抑えて一番出やすいマシンを見つける賭け方が理論的にわかってしまったのです。
CrazyStoneは次の一手候補をスロットマシンのように見て、賭けていきます。そして、勝率の良さそうな手を見つけたら、その局面については一手先、つまり相手の次の一手候補についてスロットマシンのように見て賭け始めます。良さげな手ほど先へ進めるようにしたのです。
これはモンテカルロ木探索と呼ばれています。モンテカルロはカジノで有名な町ですね。「木」というのはコンピュータの専門用語で、先が別れていくようなデータ構造のことをいいます。
このようにCrazyStoneは、局面がどのくらいいいかをランダムに最後まで打った勝率で考え、手の選び方については出やすいスロットマシンを選ぶようにして選び、有力な手については先を進めて同じことをするようにして、従来のコンピュータ囲碁プログラムにはない強さを発揮したのでした。
ただし、本当にランダムに打つと候補手が多すぎて一通りやってみることができなくなるので、候補手をいかに絞るかが強さの磨くためのキーの技術となります。
AlphaGoはこのモンテカルロ木探索と方針ネットワーク、価値ネットワークを混ぜて使っています。候補手を絞るのに方針ネットワークを使い、勝率でその局面を先に進めるか決める代わりに勝率と価値ネットワークの出力で決めます。
そして大規模なハードウェアを投入することで、かつてない強さに到達しました。
下のグラフは論文に掲載されたコンピュータ囲碁のレーティングです。
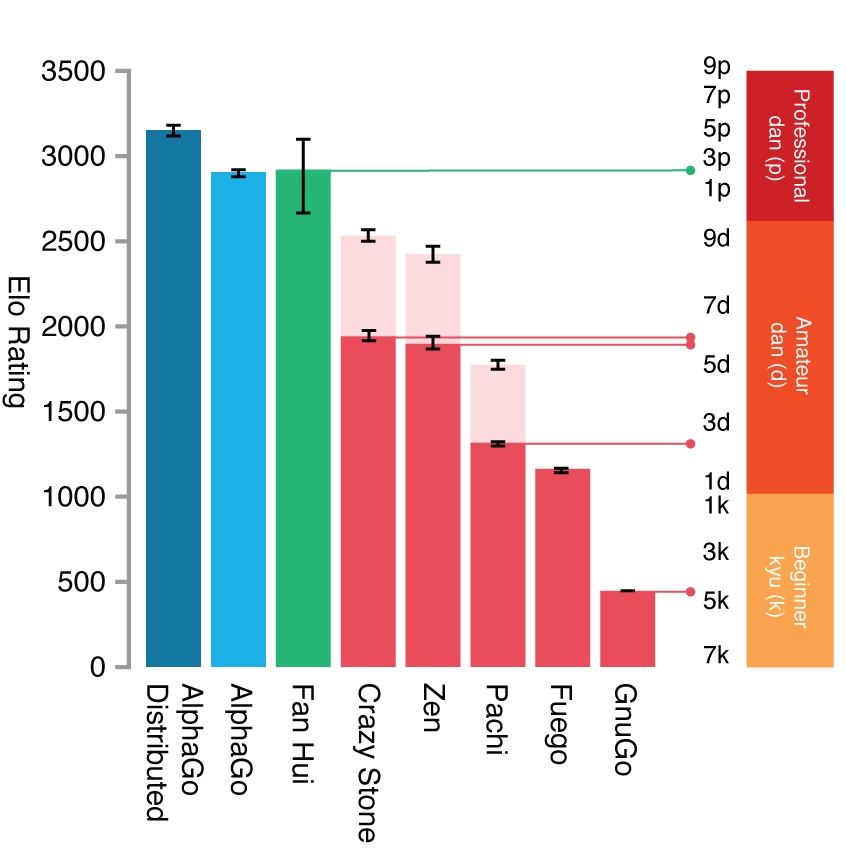
AlphaGoは3100ぐらいですか。
一方の李世乭選手のレーティングは3532と推定されています。
この論文はおそらく去年の10月ぐらいに書かれました。それから4ヶ月以上AlphaGoは学習し続けているはずです。
一体どのくらい強くなっているのか、見当もつきません。でも、明日午後1時からの対戦ですべては明らかに!